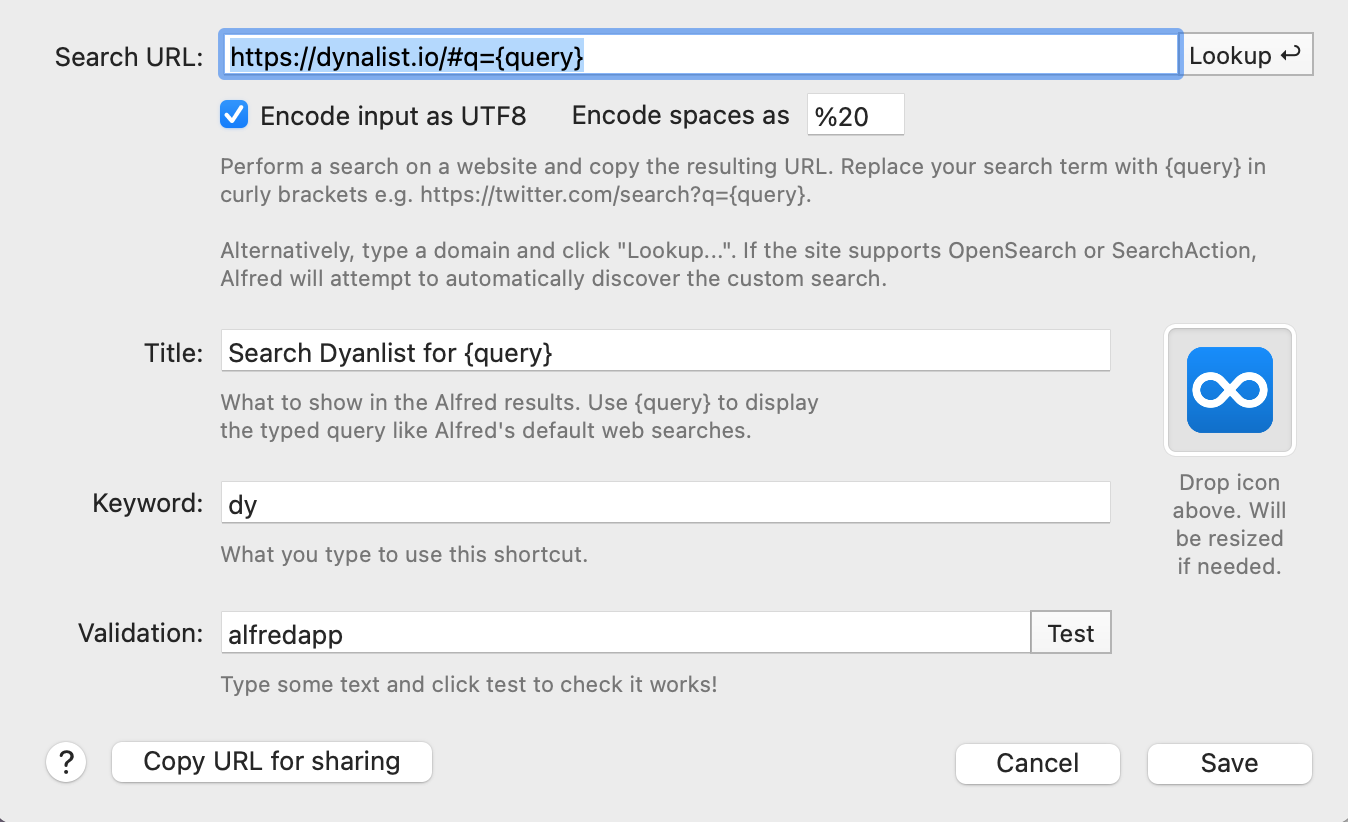
So here are my custom Alfred search settings. I’d love to be able to trigger a global dyanlist search from alfred but it doesn’t seem to work. The page just loads forever.
I am hypothesizing, but I think when you open a dynalist search URL in a new tab it first downloads the web app html/css/js files, then it downloads the entire default document, then it downloads all of the other documents, and only after all this is loaded up into RAM does the all documents search script run.
Basically it’s slow to load because it’s all processed client-side (which needs to be loaded) rather than server-side (where they leave it all loaded in the cloud ready to go)
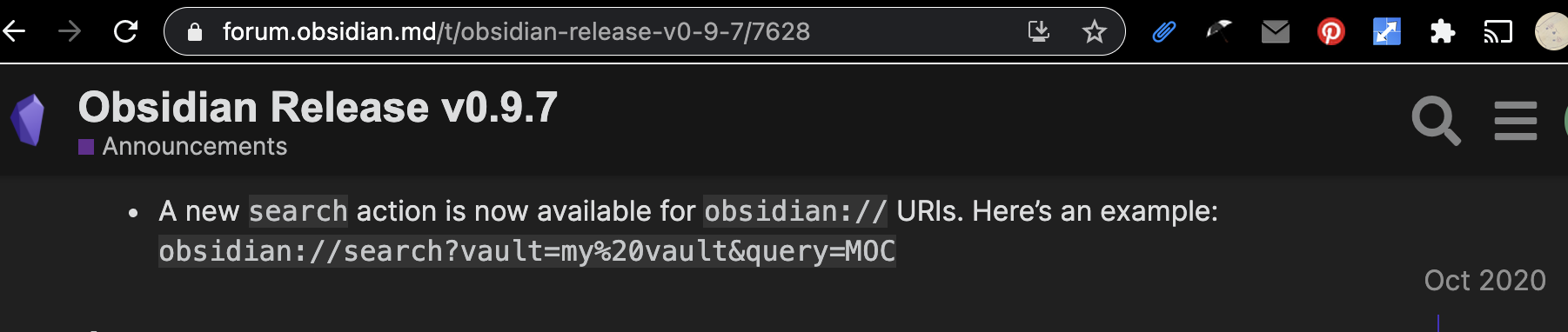
I think the best solution would be for the devs to add to the desktop app a dynalist:// URI scheme so alfred could search already loaded documents but I don’t they ever added that. They added it to their other electron app tho