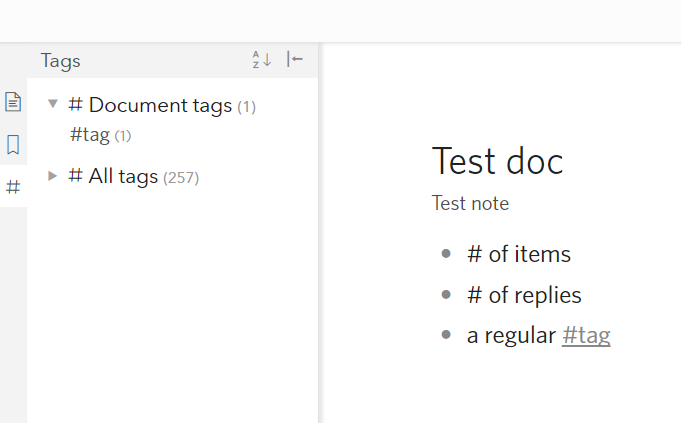
I have some unexpected entries in my Tags list.
My Tags list includes ‘@’ (Just the ‘at’ symbol by itself), which when selected shows me entries within email addresses and other non-tag related entries
My Tags list includes ‘#’ (Just the ‘hashtag’ symbol by itself), which when selected shows me 61 (of a total of 751 tags) of the hashtag symbols at the beginning of other existing tags. For example, when I click the ‘#’ Tag, it shows me #Weight with just the hashtag selected. #Weight also appears in the Tags list and functions normally. There is actually 61 ‘#’ tags in ‘Document Tags’ and 63 ‘#’ tags in ‘All Tags’
My Tags list includes a ‘#1’ tag that is the suite number from within an address. Any way to detect addresses and exclude them from tagging? Or maybe provide an ‘Ignore tag’ option to weed them out of the tag list?
Environment
I’m using the web version of Dynalist on the latest version of Chrome for Mac OS, and on an up-to-date Chromebook. I see the same results in the Dynalist app for android on a Pixel XL running Android 8.0.0.
Additional information
Anything else you think would help our investigation, like a screenshot or a log file? You can drag and drop screenshots to this box. For large amount of text, try putting them into something like Pastebin.
Same issue, I was going to log this possibly. Also the new sort setting is not remembered, even though I’d rather have it always sorted. Perhaps I need to open a new one on that?
Yeah please do. It’s sorted by # of occurrences when you refresh/restart app.
Some things (like which format you last exported too) are not persisted (remembered across sessions), since they are not as important. Tag sort is probably one of the more important things.
I see that this was addressed in the latest update, and the @ has disappeared from my tag list, but the # still exists. Strange thing is it shows there are three results, but when I click it in the list, the search shows every tag that exists since it’s searching for #.
Actually, I just pulled it up the app on Android, did a refresh, and both the @ and # are still in the Tags list, seems the fix didn’t work there at all.
I still have 3 tags reported for # in the my tag list. What is the expected behavior when a hashmark is used in regular sentences? E.g., if I have notes like “need to reduce # of bugs”, is that supposed to count as a tag?
I wanted to find which 3 items are being counted, but this is very hard. Clicking # just launches a search with “#” character, which identifies hundreds of items. If I search for "# " with space to find sentences like above, I get more than 3 results.
It should not be recognized… I can’t figure out why you can still see # in tag list… Guess what we can do is manually exclude # and @ from the tag list for now while we continue to debug the issue.
Let me know if you can find an occurrence of # that’s being recognized as a tag.
Strange that we both have 3 results for #. Related to this is a feature request I’m going to make. The ability to ‘hide’ or ‘ignore’ certain tags. I’m thinking of, similar to you, those non-tag uses of the #. Like an address that includes something like ‘Suite #200’. It would be unreasonable to expect the software to properly predict every use of a tag, so having the ability to ‘ignore’ specific instances in our documents would be a good work-around to keep our lists clean, without missing those things we really want to be tags.
While I support in general the feature to hide certain tags, that’s almost unworkable for me, as I have too many I’d have to do that for. My dream feature would be to ignore tags starting with a number, which would also fix your “Suite #200” example.
We use BitBucket here for code reviews, and pull requests are numerically numbered. So any time I reference an email subject, for example, in DL that’s a tag in the list. Just a small taste:
@Shida, the tags are probably being indexed from real data like this, typically when people use # as shorthand for the word “number”, which is quite common. From my real data:
Could you refresh (web) or restart (desktop) and see if that clears it? What Shida meant is that examples like those shouldn’t be indexed at all, so they might be ghost tags and are clearable on refresh/restart.
I’ve restarted Firefox since then, which certainly refreshed the page. Also just now logged out and back in. The # (3) is still there, sorry, along with its useful friends. (In case you may ask, #1x1 is a non-junk tag, but I would be happy to rename it to #OneOnOne if numerics became ignored)
I’m happy to try something else, if you have suggestions. I agree that with newly created data, the empty tag does not seem to appear. But for historic data, it seems to be there.
Since you can’t click the tag to see its instances, only launch a search with “#” as default, it’s really impossible to know what it’s indexing (for me). I tried adding ##, various combinations of spaces, etc. My 2 suggestions from real data from above also don’t make that tag register in a new doc.
However, the # (3) for me is a super-minor issue, compared to the others. This can be the bottom of the backlog With 100% numeric tags removed, the list is already really cleaned up. Now if trailing punctuation could just be ignored, the tag list would be nearly perfect. After much manual cleanup, I still have stuff like this:
That’s weird, as we re-count the tags every time you restart/refresh, so it shouldn’t matter which tags are new and which are historical I hope we can figure that out soon.