I use this fairly frequently, OCR (Original character recognition)
Basically, when I take notes on something that has a long outstanding amount of structure (Very Long PDF’s, books, lynda.com courses, etc) I normally try and copy their outline format
Every website is a bit different, some websites you can verbatim copy down lists of information (freecodecamp)
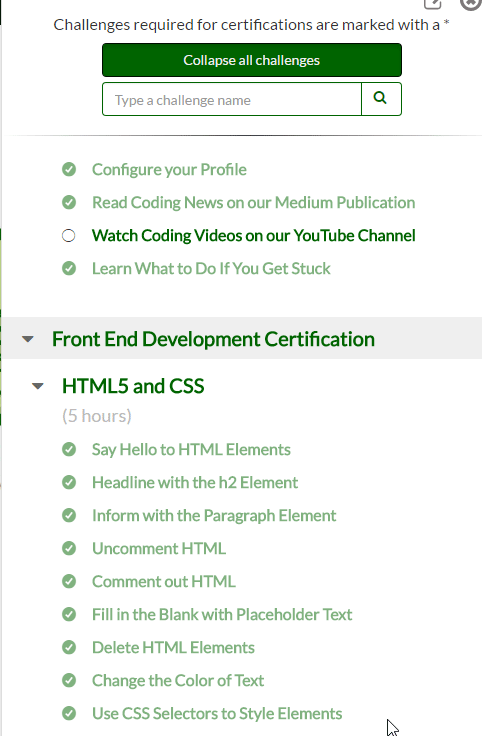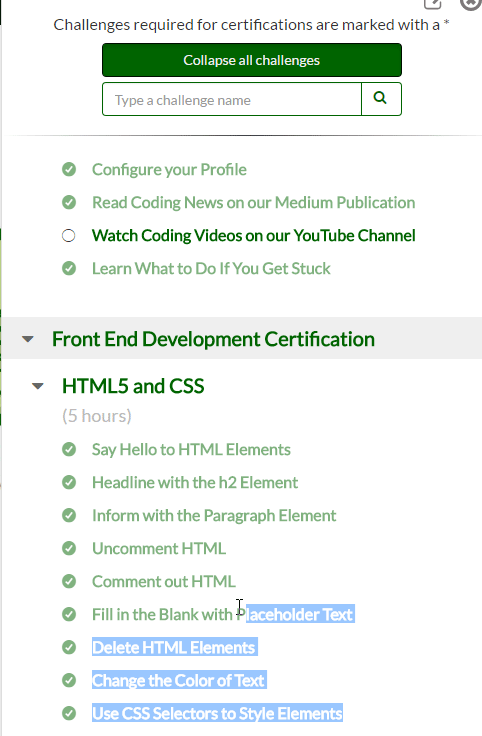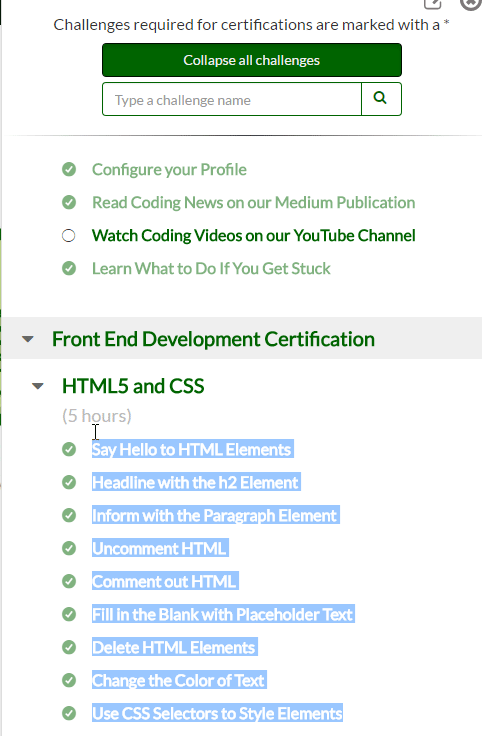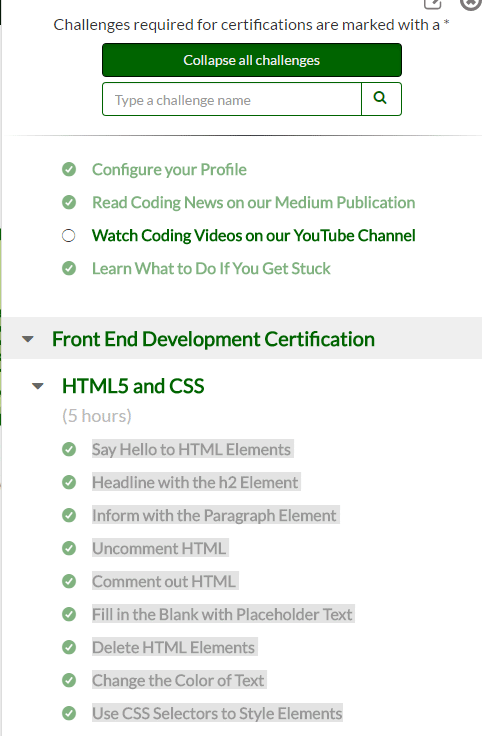
However some other sites you cannot easily copy down lists of information (lynda.com).
Its a pain to copy or rewrite things manually when I could just webscrape the data instead into a list
So I normally just run OCR recognition on anything I am going to copy and paste using shareX. I use it all the time to screengrab serial numbers for work from pictures, things I cannot copy paste due to that websites’ format etc
Sometimes, I’ll just make an image link full of just plain text similarly on how you’d use pastebin or github gists, except I use images that can be previewed with imagus chrome extension
Example of embedding text in an image, to extract back out
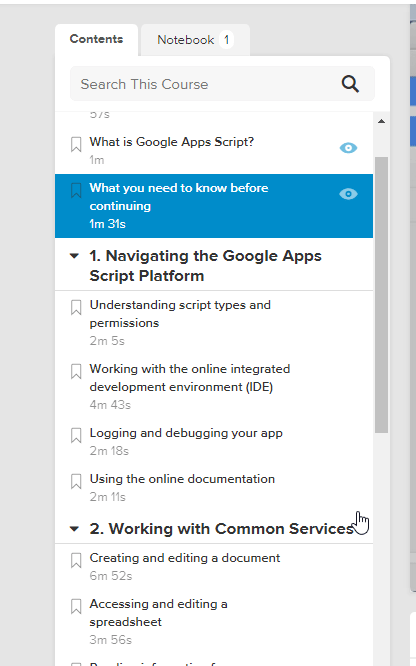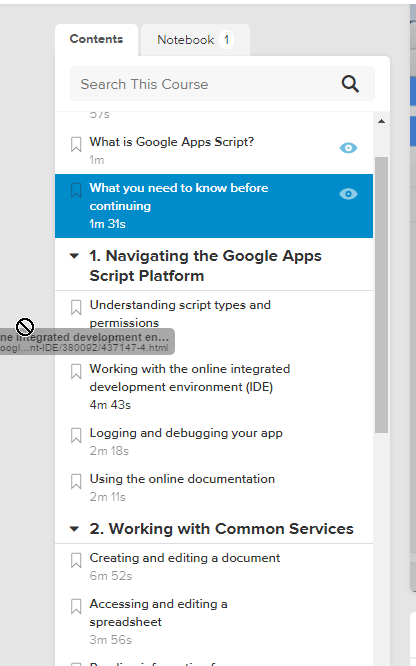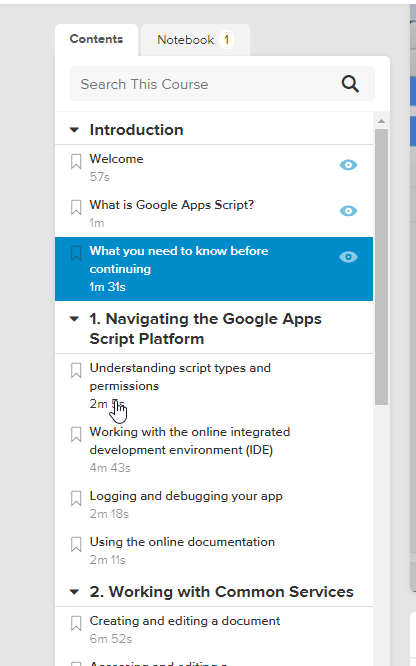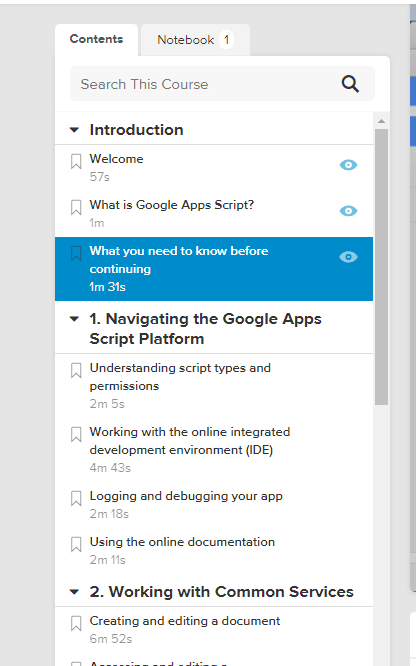
Example of using OCR recognition with lynda.com, which doesn’t allow you to copy paste the outline
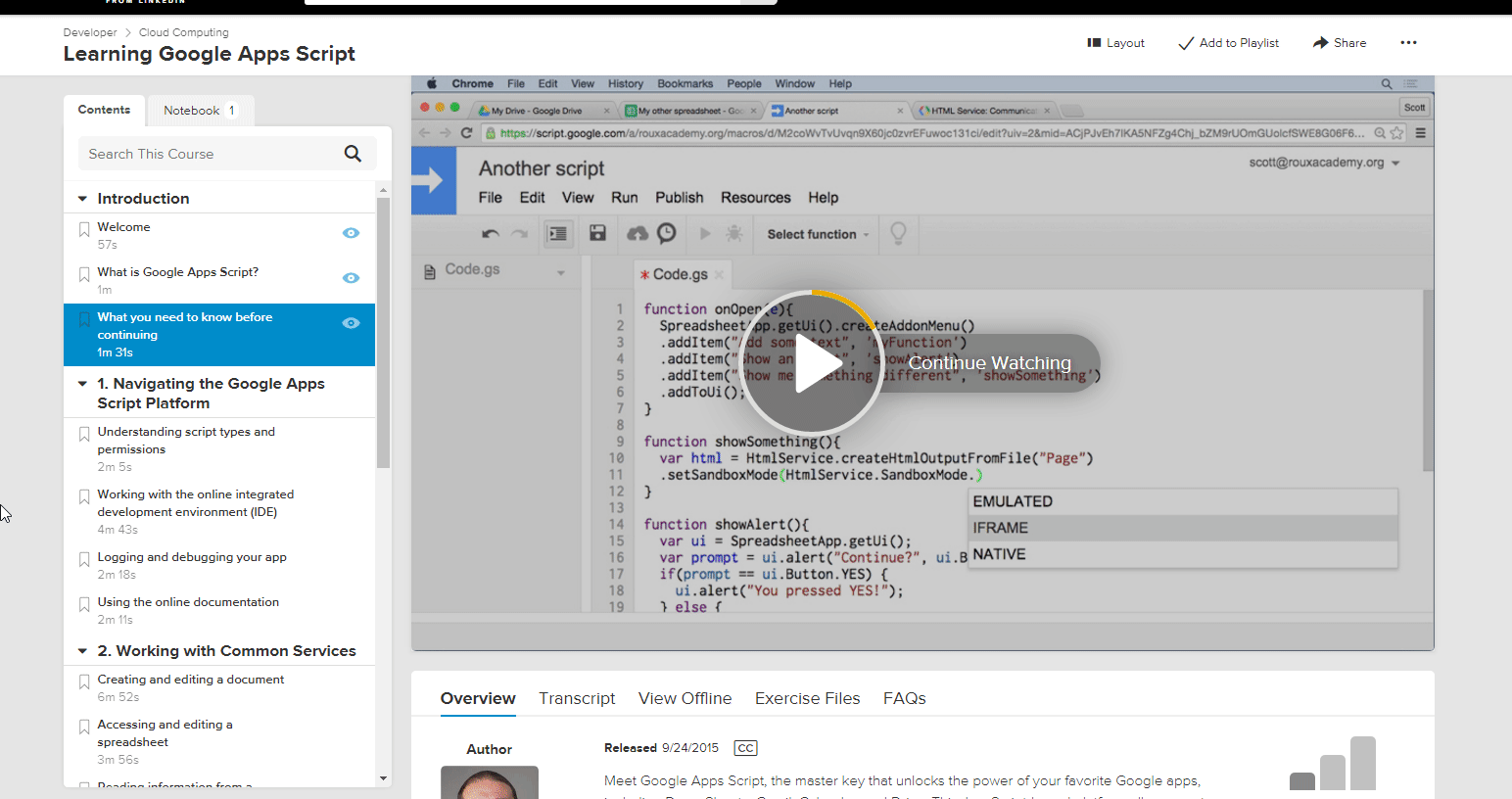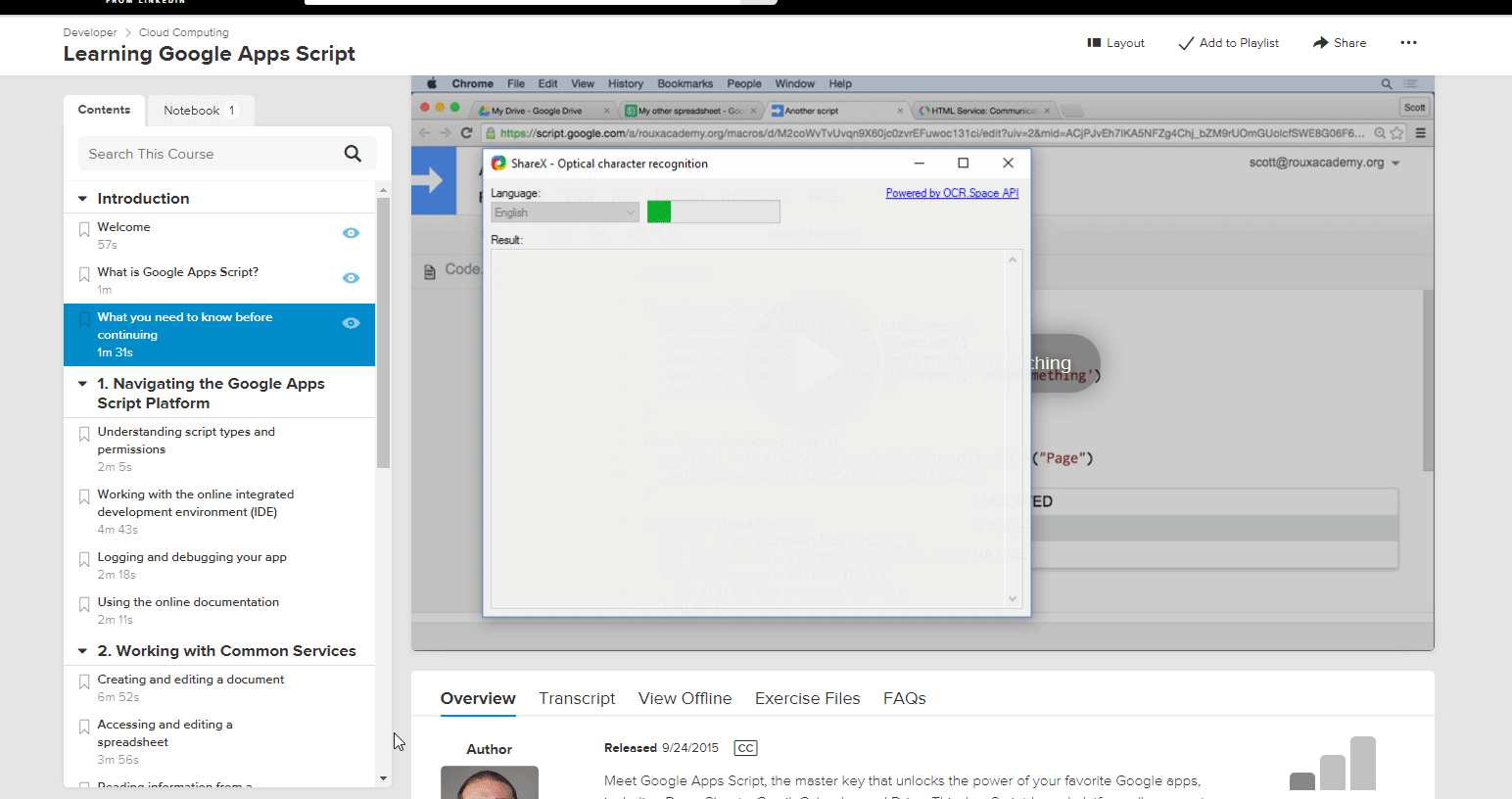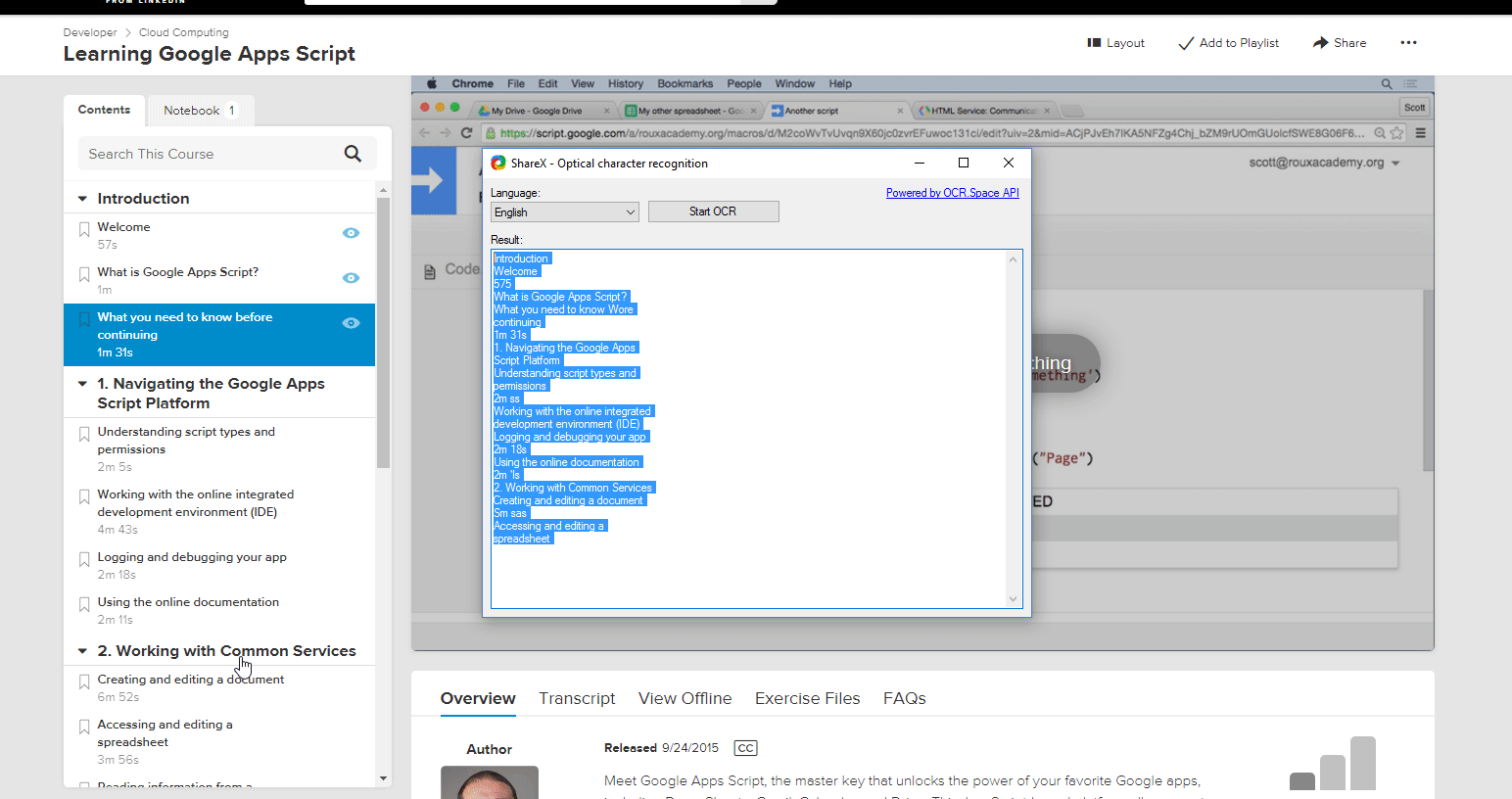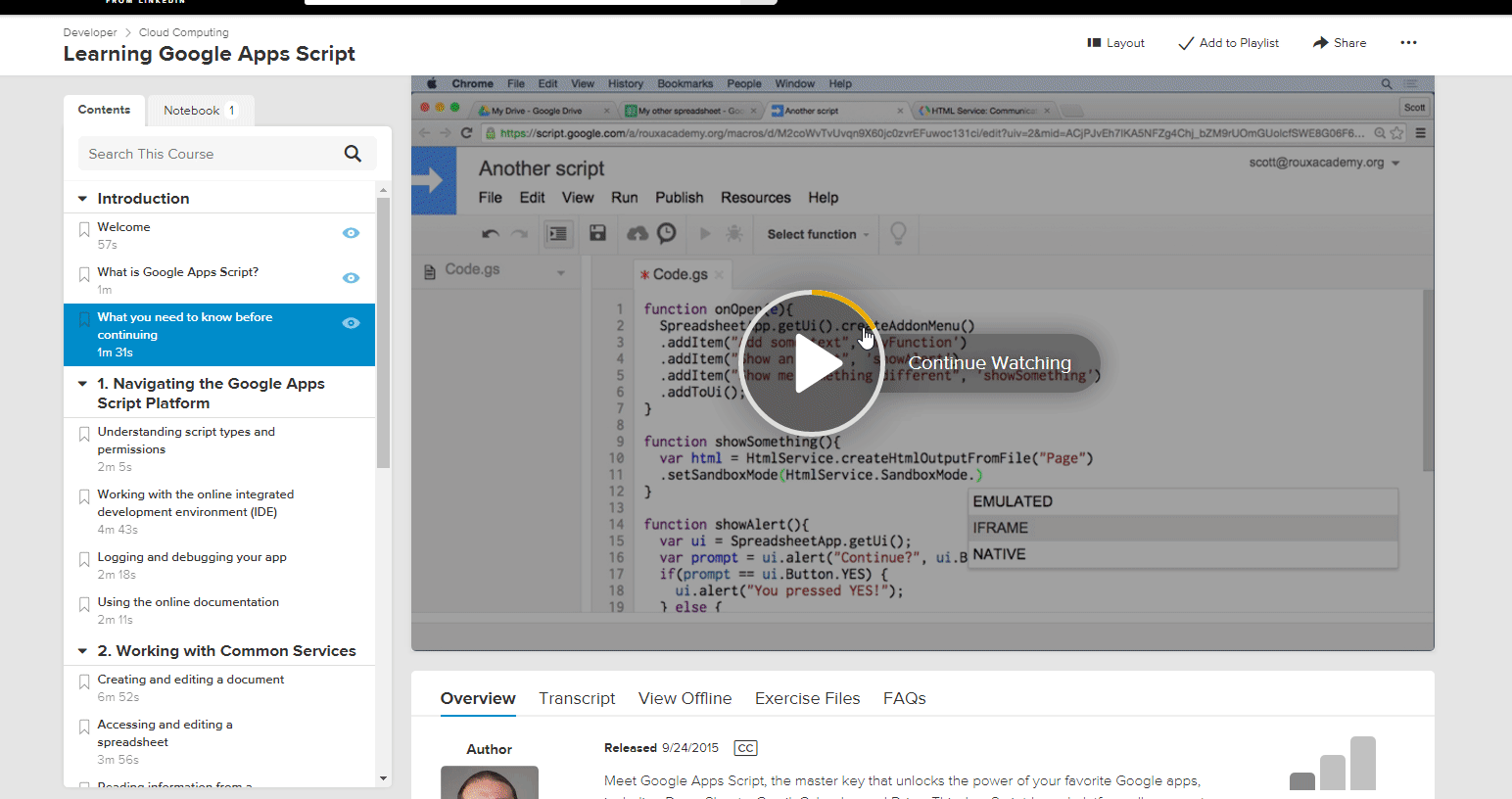
It has an accuracy of about 95%. “1” and “l” generally get mixed up, sometimes formatting gets wonky, but I just clean it up afterwards, doesnt take long
What’s good about this as well, is I can simply just take a picture of something →google photos uploads it automatically → navigate to photos.google.com → run OCR. This is especially useful for textbooks as well, if I don’t have a PDF version of it
You can do this with 3rd party programs (officelens, photoscanners), but with my methodology, its just one simple workflow, one hotkey away, without having to open this box and fiddle with the another android program, etc
I use this OCR recognition a lot when I make annotated images, and sometimes I want to extract that short paragraph afterward, without using native object files, etc
Other times I use OCR: I use it when citing references, so I might say take an annotated screenshot from stackoverflow to cite my references, but then when I revisit it later, I can just preview the image and grab out the data without ever visiting the site.
It saves me from (1) opening a tab → (2) navigating to the specific information → (3) Copying information → (4) Navigating back to dynalist → (5) closing out the tab.
EDIT - OCR for feedly / Inoreader
I’m in the middle of redoing my entire Feedly vs Inoreader setup, so I can aggregate things and information on the web easier
I used feedly premium for well over a year and I think inoreader premium fits my needs better
Its kind of tedious but I add every feed manually into inoreader one by one. I also want to have an exported list of all the items I put in inoreader into dynalist for backup so I know how i organize it. Or do whatever I want with the data. Example:
this is how I use OCR here:
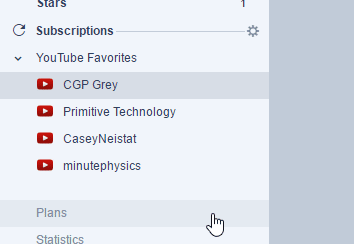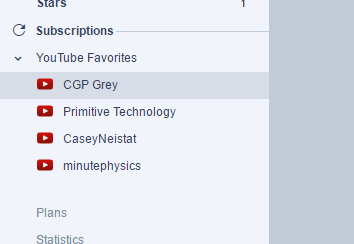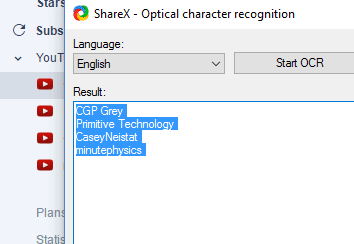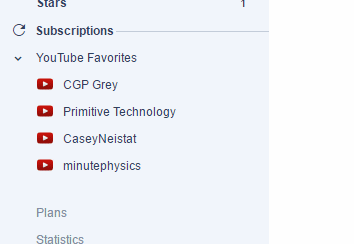
I could also just create a backup screennshot of what my inoreader feeds look like (with images) and then scrape it later with OCR
EDIT EDIT - OCR for subreddit subscriptions
I have 2-3 reddit accounts as well for different purposes (different inboxes, one for work, one for mobile, one for whatever - some public some private, etc) Sometimes I want to extract out all my subreddits really easily as well
Just go to “my subreddits” Zoom in a little so OCR can work better, then proceed to extract
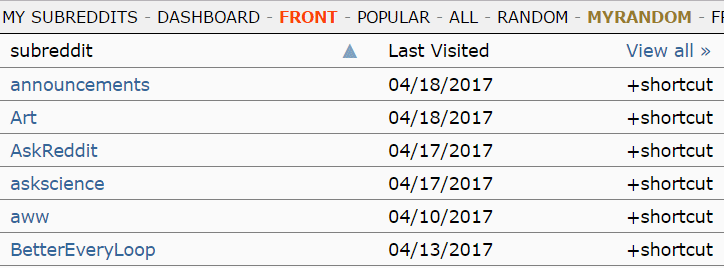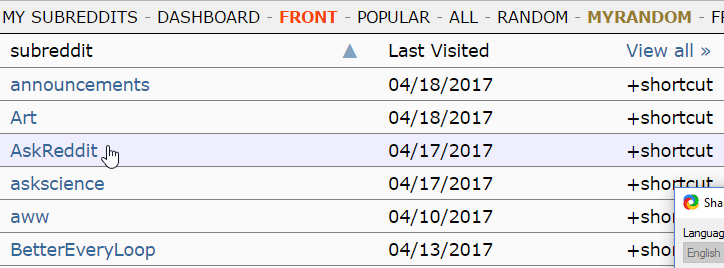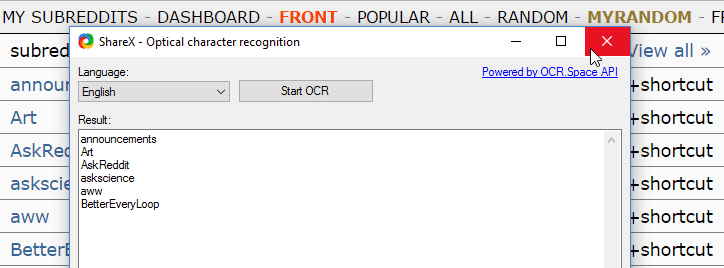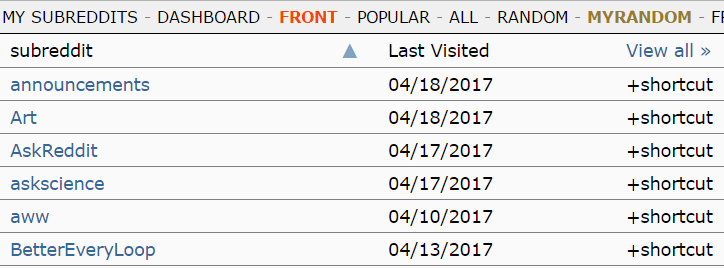
Then you can use that list to subscribe to your INOREADER / FEEDLY to subscribe to wherever. Or run bots, data aggregation, anything you want really
I subscribe to a lot of random stuff just for “subreddit discovery / informational discovery” but a lot of times I don’t necessarily look at those subreddits often or simply forget to when on reddit
So I can use INOREADER / FEEDLY to manage that better manage the information afterwards
EDIT EDIT EDIT - inoreader specific
just some quick notes about inoreader. I like the premium trial alot. used it for 2 days. Feedly feels like childsplay compared to inoreader
it works really well for finding new data sources. Anything with public data on the web can be scraped into an RSS. Such as newest questions “tagged with Javascript” on stackoverflow, Blog titles, instagram feeds (National Geographic), subreddits, quora “Specific title search rules”, etc. Twitter feeds, facebook feeds (but would have to integrate with my facebook). I can probably subscribe to this forum as well… but its not consistent though. I could probably RSS specific reddit users if I wanted too to, there’s a few that post really good content not found anywhere else on the web
also, it lets me preview the entire contents of a blog site, in the order blogposts were made, in an email format. This means I can navigate every blog post made on a website in probably 1/4 of the time now. No fiddling around figuring out how each website decided to organize itself. I do this for workflowys blog / webinars.
Also, for youtube playlists and videos. Youtube is really slow to navigate between different channels and has so much wasted real estate on it. Also, it has some of the worst UX/UI design as well. With inoreader, I can preview every video a channel has uploaded, star which ones I’ve looked at on channel, look at ones recently uploaded. Or subscribe to a playlist, this is good for ongoing tutorials
I could probably even RSS my own account in stackoverflow / each stackexchange account since the user preferences / mailbox features are kinda really awful since i can’t mark things in my inbox as unread.The only way I can use a TODO list for this is checking my email every now and then and just periodically check whether my questions were answered or not. There’s a lot of applications of webscraping yourself in the context of GTD (e.g. 3rd party apps, IFTTT, hootsuite, RSS inoreader, FollowUpThen / Gmail plugins, etc)
Then I can apply filter rules like "ignore if the item has “Comment” in it. Example:
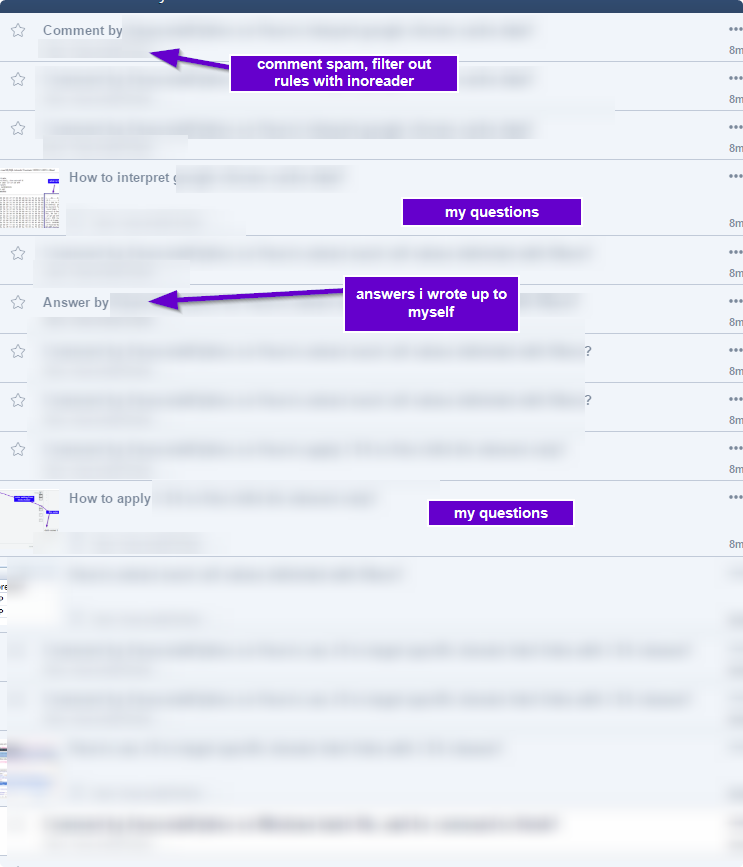
I fiddled around with most of the shortcut keys and I find it much better than feedly. I like knowing everything and anything going on in the world of importance, but don’t really like spending a lot of time navigating between different lists
Also, I can RSS specific stackoverflow users I want to follow, because they have similar problems and questions that I have on similar projects. I can search for the questions they ask without visiting stackoverflow first, etc
I mentioned earlier in other posts I like to generate lots of ideas (good and bad ones), but I need some fast systematic way (neural network/algorithmic) means to validate whether those ideas are good or not. This is one of the ways I do it
In the end I back up all that data into dynalist. Or maybe vice versa, I use dynalist to figure out how I want to organize inoreader. I use informational discovery on whatever platform the information is on though and RSS (e.g. reddit, stackoverflow) and still use whatever method is most convenient as well (Reddit “Save Comment” , Reddit “Subscribe” to subreddit)
Also, I use the following conventions with inoreader
STAR → this is a bookmark. Hotkeyed to “S” key
“Like” → this is how I know what I’ve read, without using system read/unread parameters that most RSS things use. Hotkeyed to “L” button
