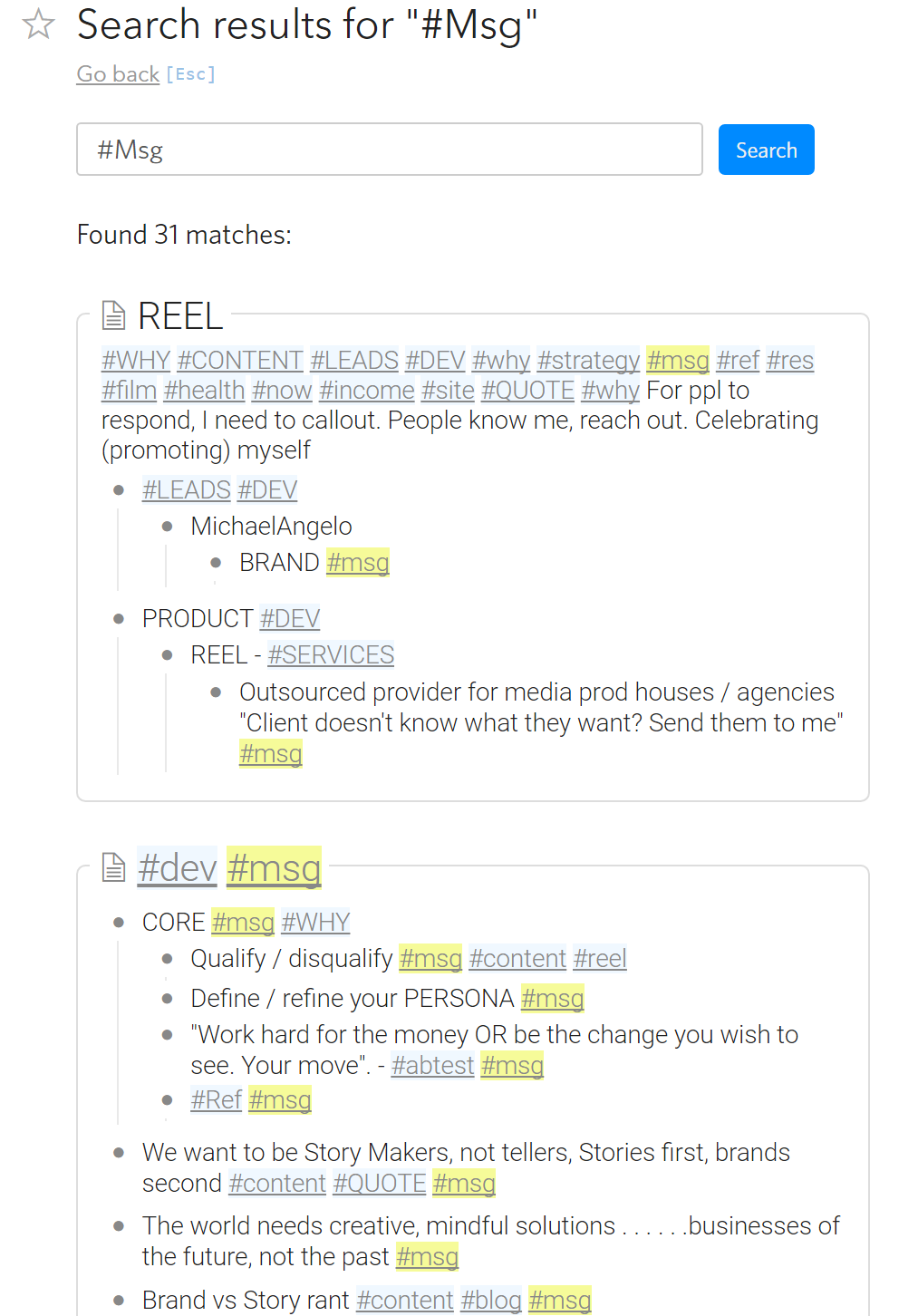
Import data with tags of varying case (e.g., from Workflowy), or:
Create items with mix of #someTag vs. #SomeTag
Observe how both now show up in auto-completion and tag pane, as if they are different things.
Expected result
Only to have the one instance of the tag show up (probably first), not to have duplicates.
Actual result
Many duplicate tags now show up in auto-completion and tag pane.
Environment
Desktop browser, not platform-specific.
Additional comments
For search, searching for #someTag also finds/highlights instances #SomeTag, so case sensitivity is not consistently enforced.
WF indexed tags case-insensitive, so I have a large mix of imported data. Cleaning it all up is difficult, there’s no search/replace. Depending on place in a sentence, I have #Demo and #demo, for example, but it’s the same tag! Now I cannot click on a single tag to find all its instances, and auto-completion is cluttered.
I propose all tags are indexed lower-case, and their used display is the first instance found in the document (since tag list is updated all the time with changes anyway).
Hopefully no one should be relying on current behavior. Previous posts, such as this one, never mentioned relying on case sensitivity.
The problem is more complicated with tag pane. For example, if you have #someTag, #someTAG, #SOMETAG, and #sometag, which one should be shown in the tag pane?
The easiest and straightforward answer would to be always use all lowercase (thus “#sometag”), but that hurts readability for many tags.
Or we could count all possible combinations of the same tag (case-insensitive), and try to decide which is the most common spelling, but from our last internal discussion on this, this adds too much complexity to our code that it’s not really worth the benefit (we could be wrong on this).
I know we cannot expect users to always create tags using the built-in autocomplete, but I’m kinda curious why do these tags exist in the first place. If WorkFlowy enforced only one spelling, why are there duplicates? Were they typed in manually?
Yes, they were typed manually in WF. That’s what I meant above by “Depending on place in a sentence”. WF treated these as the same tag:
#CodeReview needs to be done
Feature X has passed #codeReview!
This is just an example, I think for my real data it’s actually more common with single-word tags, like #demo or #discovery.
The problem of which one to choose is one I acknowledged above. I thought about lower-casing all as well. I think separating how you store tags vs. display is definitely a part of that.
Looking for the most occurrence does sound very slow. That is why my suggestion is to use the first occurrence for display purpose. I’m pretty sure this is how WF solved it, and I think it’s actually reset each time the doc is indexed. Since tags auto-completed from the current scope, you could have #Demo or #demo show up in the auto-complete depending on which occurred first; this seemed to work just fine.
But seriously, almost anything in DL that eliminated/combined the dupes would be fine with me as a solution. I know auto-completion is a standard response to data issues (e.g., with tag trailing punctuation), but DL supports import! If non-compliant data is not cleaned up somehow during import, or at least warned about, this leaves things in a non-ideal state. And supporting mixed case is a huge advantage in readability, which is why I see this issue.
It’s possible to auto-complete tags from all documents though (it’s in the options), which would make it a tad more complicated.
Another thing: wouldn’t it annoy some users that they have no control over how the tag is displayed? They probably won’t understand the first tag in the first document decides how it looks in the tag pane, and found out they can’t really do anything with it.
Or maybe they can just rename it to a consistent case? Do you think they would do that?
@Erica, I’m glad you’re thinking in-depth about this implementation. I think there’re lots of ways to explode this feature to make it more complicated, such as allowing some preference to control display, allowing user to rename tags for custom display and storing that, etc.
But from looking at my (rather large) list of real tags, I would be 100% fine with them being all lowercase. None are longer than a few words, and this would not lose their readability. The huge win would be combining dupe ones. I obviously don’t know about others’ data.
If you do go with the “1st usage sets display” approach, clicking the tag already shows you its instances (well, kind of), so a user would see right away where the top hit came from.
Another easy approach I can think of is a hover tooltip over the tag that shows found variations. This is more informative without a lot of new UI. You could do this both for lowercase and 1st use approach. E.g., I hover over #codecoverage and it shows me that it found #CodeCoverage, #codeCoverage. These could even have their own sub-counts, so the user could decide which one should “win” if they do manual cleanup (though I wouldn’t care about this).
Just to echo what I said on another thread, a good guideline on hashtags is “What would Twitter do?” There, tags and mentions are unambiguouslycase-insensitive.
Linking to #sharesomegreatnews still finds the common tag (just to pick a random trending one)
Twitter is not confused when I mention @eriCA instead of @Erica, and will go to that person
Yeah I agree, we never thought tags should be case sensitive, it was somewhat from the laziness when implementing tag pane. We went through the thought process above and decided to just show them separately.
So yeah, they should’ve been case-insensitive if we had sorted out this issue back then.
No that’s not what I meant, I meant that we knew tags should be case insensitive from the beginning (we use Twitter too and we know how it should work), but because we didn’t sort out the issue we discussed here back then, it wasn’t properly handled. It’s an explanation for the status quo, if you want to think of it that way.
Sorry for the late reply, we have been in the middle of an office move recently, and started replying to the piled up forum threads in the past few days. The order is a little random, and I’m sorry it hasn’t gotten a reply yet.
On top of the details listed, the search results don’t even return the Case-Sensitive tags, they return ALL case-insensitive tags. So, cleaning up the mess of tags that I’ve needed to clean up for over a year now just got even more painful .
Can we please get a confirmation - is anything happening with this?
If so, eta?
Something like that – for tags under “Document tags” (not for “All tags” yet), you can right click, select “Rename” and rename it to another case-sensitive tag.
I tried renaming “#Msg” to “#msg” and it seems to work.