This post for hiding / viewing checked items kind of ties in with my macro button response below
Also, Piotr’s tamperscript for auto-sorting is pretty much exactly the UX behavior that should be used for the above reply
Another feature I would really like using dynalist’s API (probably possible with just tamperscripts) is to give dynalist more “Database-like” functions for filtering and viewing data
this is already achieved with tags already, but I feel like you would just have to use way too many tags to achieve this effect (each tag = one filter). Meaning if you wanted 2-3 filters (using dynalist’s search parameter), every item would need 2-3 tags, which is really redundant, making the overall document difficult to read
Not only that, you would have to go into search mode in dynalist, meaning you only limit yourself to one set of tasks at a time (viewing data, but not really entering data)
Tamperscript / API plugin proposal
what i propose is following:
More hide/view data similar to database filters (similar to excels hide columns, hide rows, etc)
Essentially this would give you more hide/view controls of your data overall
The best example I have and why I would use it is such:
Say I want to outline a very long file structure (ecommerce file folders) so I can understand the data as a whole.
This is what my data looks like, or just a snippet of it. Its inherently unorganized since the child/parent relationships aren’t well understood, so a RDBMS setup using airtable is out of the question

I want to bookmark different “views” of this data as I work and change filter structures so I can know what folders do what, as I learn more about this system
So I might have various viewmodes for my files like so: (Hide/Check box) and (Collapse/Uncollapse bulletpoints)
Each view filter would be saved into the tamperscript, kind of like what you do with video game saves
Below is the entire proposal and what the tamperscript does essentially , in one image mockup
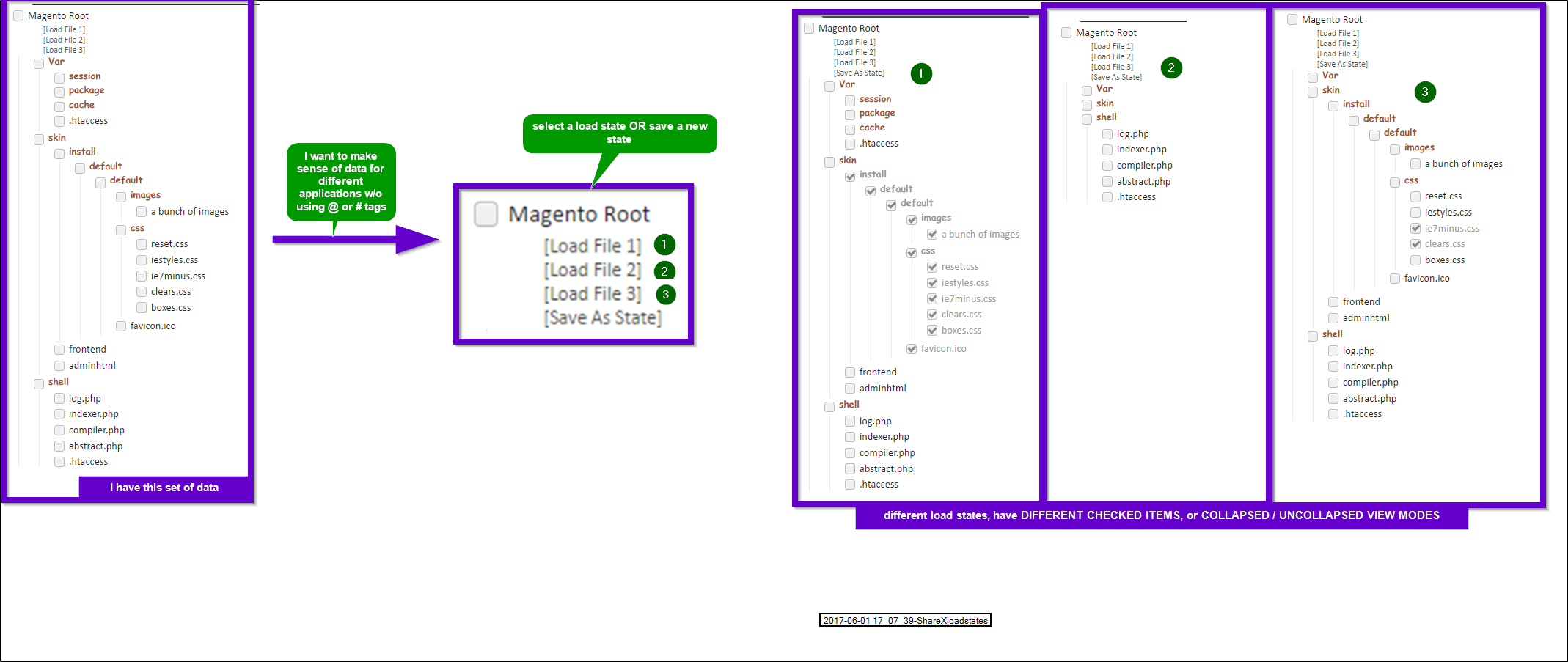
TLDR
see above image
Basically, my tamperscript / api plugin wishlist is to have “save” / “load” states for specific views. These control and change following:
- collapsed / uncollapsed items in that list
- checked / unchecked items in that list
similar to database filtering views, excel “hide rows and columns” that kind of thing.
More database-y like features for outlining and organizing very large complex file structures by hiding things you want to see / don’t want to see based on task
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
EDIT 6/4/17
This is semi-related to the above feature for collapsing / uncollapsing and checking / unchecking list
Its a “save” / “load” state feature pulling in Dynalist’s API for the primaryKey of the node, or just using the “Creation date” as the primaryKey through javascripts DOM
It would be based on unix epoch time, Unix time - Wikipedia or iso-date format Use international date format (ISO) - Quality Web Tips , but a simplified version of it
optionally hexadecimal / 64 bit encoding is possible here too
Use the following format for saving / loading save state data (comma seperated values)
Data on my browser from dynalist is stored as such
<div class="Node-bullet" title="Created at 12:51:00 PM on 6/4/2017, last edited at 12:59:15 PM on 6/4/2017"></div>
I would use the “Created at” time to define where the bulletpoint is at. Since this value doesn’t change
so if I had the following data:
✪✪ A [creation date: 12:51:00 on 6/4/2017]
“A” would be converted like so:
2017-06-04-12-51-00 (YYYY-MM-DD-HH-MM-SS)
remove hyphens. Assume GMT timezone / option to define in settings
20170604125100
Optionally convert to epoch unix time or leave as is
Store the data as follows. So if the following save format would be
how this would all work (top level childpoints)
Basically if I had the following data in dynalist, I could save the sorting order based on creation date
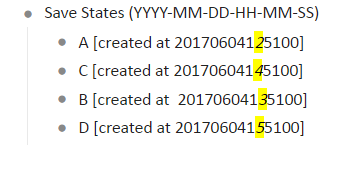
I highlighted the difference in stamps here
I would click a tamperscript
It would save and output the following data inside the “Save states” note
#[save1 | 20170604125100, 20170604145100, 20170604135100, 20170604155100]
Because if I wanted to run piotr’s autosorting / tamperscript this is how I would find the original way my data was sorted
Optionally, this data could be saved, either in dynalist directly, or through a 3rd party server, and referenced through another primarykey
issues
above is how i would implement a method for saving the order in which bulletpoints appear, if I wanted to change up the order my dynalist toplevel bulletpoints appeared for working on different things
there’s a few issues here that this sorting / save/load state wouldn’t cover
- child of child node order
- Deleted or newly added bulletpoints
I would have to use an API + an external server / RDBMS storage to handle this. The RDBMS layout would look like this though (per bulletpoint assigned)
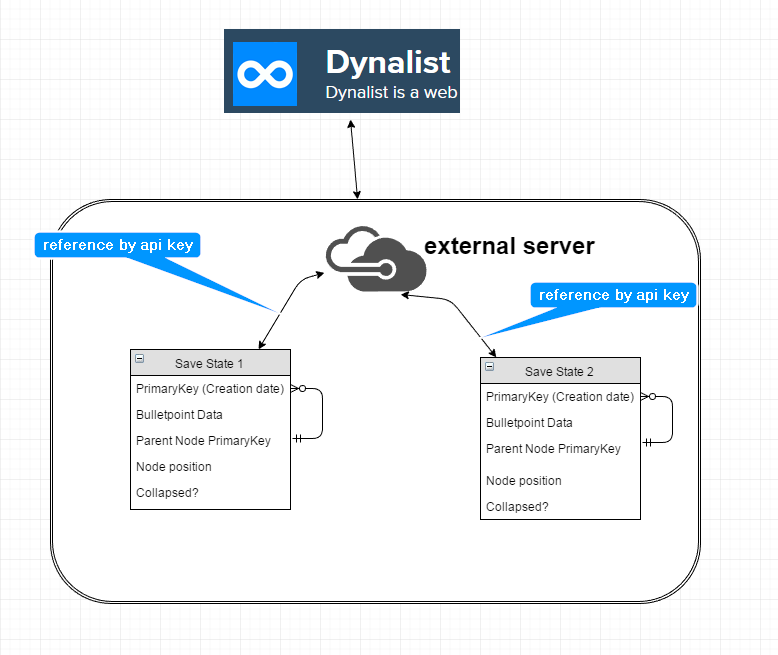
It wouldn’t necessarily actually need to use a dynalist API at all, since the data can be read straight from the DOM, but it would make retrieving data much easier though / sending back data as well. If no dynalist API available ,then it would have to be an apikey sitting inside the parent bulletpoints note instead.
tl;dr
look at the last image. it sums it up
basically, I want a way to save a specific “View” of data
- What bulletpoints are collapsed
- Which ones aren’t
- Which bulletpoints to show / hide
- Ignore newly added or deleted bulletpoints (or update on an ongoing -dynalist API basis / calls)
This would give dynalist more database-y features for filtering data and getting a better context of more complex data (just think of adding excel-like features into dynalist). Normally to do this right now you would just use tags.
using dynalist API (or even a tamperscript) to an external server or locally cached data for storing “Save states” would make things easier. Namely, the “Save state” data would just be referenced by one key, which in turn has a simple relational database-style setup with only 1 table per save state
This is great for outlining and taking notes of a complex document. Like for instance, you wanted to make sense of 100,000 lines of code, you could outline it first in its hierarchial file form in dynalist, take notes in each area, “Save” the states and preview what things you want. The use-case for this is mostly in the science / computer science / engineering field though