
I have some unexpected entries in my Tags list.
My Tags list includes ‘@’ (Just the ‘at’ symbol by itself), which when selected shows me entries within email addresses and other non-tag related entries
My Tags list includes ‘#’ (Just the ‘hashtag’ symbol by itself), which when selected shows me 61 (of a total of 751 tags) of the hashtag symbols at the beginning of other existing tags. For example, when I click the ‘#’ Tag, it shows me #Weight with just the hashtag selected. #Weight also appears in the Tags list and functions normally. There is actually 61 ‘#’ tags in ‘Document Tags’ and 63 ‘#’ tags in ‘All Tags’
My Tags list includes a ‘#1’ tag that is the suite number from within an address. Any way to detect addresses and exclude them from tagging? Or maybe provide an ‘Ignore tag’ option to weed them out of the tag list?
Environment
I’m using the web version of Dynalist on the latest version of Chrome for Mac OS, and on an up-to-date Chromebook. I see the same results in the Dynalist app for android on a Pixel XL running Android 8.0.0.
Additional information
Anything else you think would help our investigation, like a screenshot or a log file? You can drag and drop screenshots to this box. For large amount of text, try putting them into something like Pastebin.


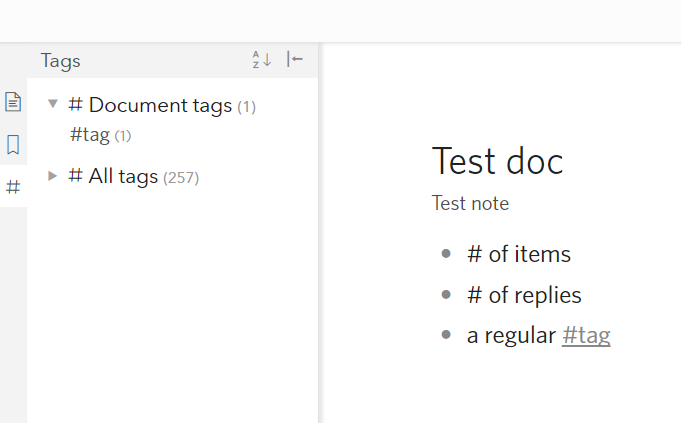
 With 100% numeric tags removed, the list is already really cleaned up. Now if trailing punctuation could just be ignored, the tag list would be nearly perfect. After much manual cleanup, I still have stuff like this:
With 100% numeric tags removed, the list is already really cleaned up. Now if trailing punctuation could just be ignored, the tag list would be nearly perfect. After much manual cleanup, I still have stuff like this:
 I hope we can figure that out soon.
I hope we can figure that out soon.